How to Manually Install Elasticsearch on Linux
Continuing with the topic of manually installing Elasticsearch, we first covered the need for manual install and performed manual install of Elasticsearch on Windows and in this post, we’ll cover installation of Elasticsearch on Linux.
There have been two options to download Elasticsearch, one via Oracle Cloud and another one via My Oracle Support. Unfortunately naming conventions have not been consistent, which adds to confusion. Best option is to download Elasticsearch 2.3.2 from Oracle Cloud. (V844470-01.zip : Elasticsearch 2.3.2 for PeopleSoft Deployment Package for Microsoft Linux x86-64 – Revision 2).
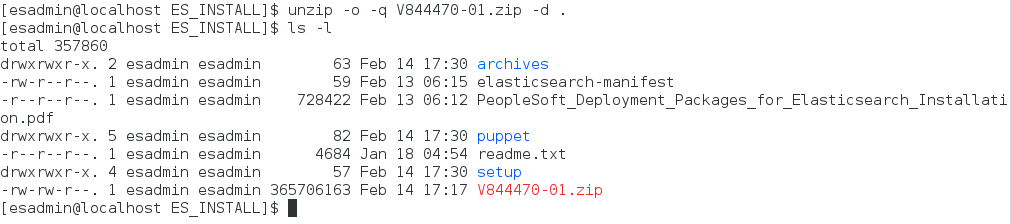
Once downloaded, unzip V844470-01.zip. You can unzip it to any directory with a new name or the same name. We’ll extract it to a directory which goes by Oracle naming convention and call it ES_INSTALL.
Navigate to the directory where V844470-01.zip was downloaded and extract it into the same directory, ES_INSTALL using the following command:
unzip -o -q V844470.zip -d .
Once extracted, you should see a directory structure like below:
In case of an automatic install wherein all the needful components get installed where they need to, we would be running the script ES_INSTALL/setup/psft-dpk-setup.sh but since, this manual step is needed in cases wherein you’re having issues running and installing Elasticsearch through psft-dpk-setup.sh, we’ll walk you through the additional steps needed in case of a manual install of Elasticsearch on Linux.
Create the following directories in the location of your choice:
- Create a directory where Elasticsearch will be installed. You can create it with any name of your choice. Oracle naming convention for the same is ES_HOME_DIR.
- Create a directory where JRE will be installed. You can create it with any name of your choice. Oracle naming convention for the same is JAVA_HOME_DIR.
Go to <ES_INSTALL>/archives and extract the pt-elasticsearch2.3.2.tgz to <ES_HOME_DIR> as well as JRE package, pt-jre1.8.0_74.tgz to <JAVA_HOME_DIR> using the following commands
tar -xzf pt-elasticsearch2.3.2.tgz -C ES_HOME_DIR tar -xzf pt-jre1.8.0_74.tgz -C JAVA_HOME_DIR
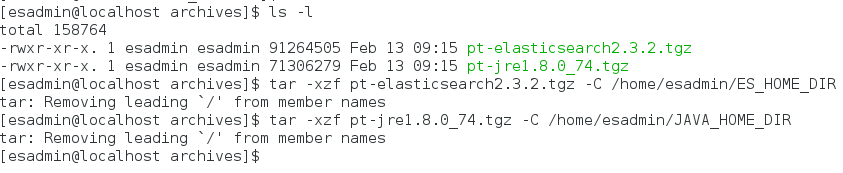
Once extracted ES_HOME_DIR should look something like this:
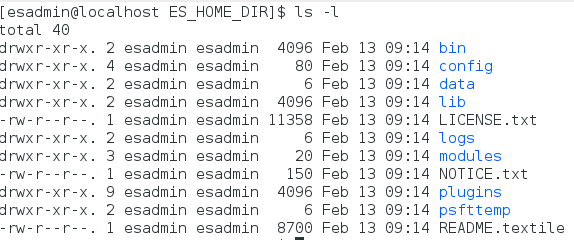
Once extracted, JAVA_HOME_DIR should look something like this:
When you do the automatic install using DPK, it invokes elasticsearch.yml and prompts you to provide input but in case of manual install, you’ll need to edit elasticsearch.yml and do the setup.
You’ll need to uncomment the following parameters and assign values to them. Sample assignment values are provided:
- cluster.name: search
- path.data: /home/<host>/<ES_HOME>/data
- path.logs: /home/<host>/<ES_HOME>/logs
- network.host: 127.0.0.1
- http.port: 9200
- discovery.zen.ping.unicast.hosts: [“127.0.0.1”, “[::1]”]
- discovery.zen.minimum_master_nodes: 3
Depending on whether you use proxy servers or not – you’ll need to comment or assign values to the below parameters (these are uncommented by default):
- orcl.proxy.host
- orcl.proxy.port
Provide execute permissions for ES_HOME_DIR using the command:
chmod -R 755 <ES_HOME_DIR>
Set the following enviroment variables using actual paths:
- export JAVA_HOME=<JAVA_HOME_DIR>
- export ES_HOME=<ES_HOME_DIR>
- export ES_HEAP_SIZE=2G
By default, Elasticsearch will make use of 2 userids – esadmin and people. Their default passwords are esadmin and peop1e respectively. Either you can use the same passwords or you can change the passwords to whatever you desire. You can also add new userids instead of the above mentioned userids. You can update passwords, create new userids using the following command from <ES_HOME>/bin
./elasticsearchuser adduser username
Change directory to ES_HOME/bin and run the following command to start elasticsearch as a process:
nohup ./elasticsearch &
![]()
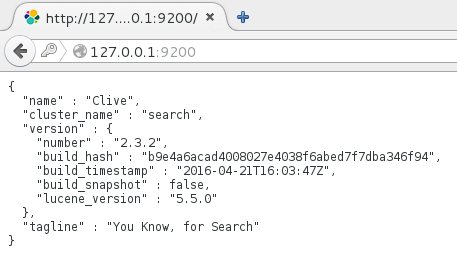
Now go to a browser and go to http://<host>:<port>
For example http://127.0.0.1:9200 — you’ll need to provide esadmin userid and password. If it is working fine, you should see something like this: