
Elasticsearch Split Brain Problem
When you start Elasticsearch on a server, you get a Node for Elasticsearch. When you you start Elasticsearch on another server or another instance of Elasticsearch on the same server, you get another Node. All these nodes together form a Cluster. With a cluster of nodes, data can be spread across multiple nodes. If you have atleast one replica per shard, any node can disappear and Elasticsearch will still serve you all the data.
Sounds interesting right? Sounds like something you want to have for your production environment. For your developmentinstances, a single node may be good enough. If something happens to that node, you can inform everyone about the outage and work on it. But not for production. For production, you need high availability and performance, which is not possible with a single node.
You can get high availability and great performance with clustering of multiple nodes.
Does that mean that clustering does not have any disadvantages? Unfortunately not.
Elasticsearch Split Brain Problem
Although clustering is good for performance and availability, it has its disadvantages: you have to make sure nodes can communicate with each other quickly enough and that you won’t have a split brain. Split brain happens when two parts of the cluster that can’t communicate and think the other part dropped out.
Let me explain with an example:
Suppose you have 2 nodes — Node 1 and Node 2 and you have just one index deployed.
Node 1 stores the primary shard and Node 2 stores the replica shard. Node 1 gets elected as a master during cluster start-up.
Then suppose there is communication failure between the two nodes. Now, each of the nodes are in dark about the status of the other node and hence, they believe that the other has failed. Node 1 being the master will do nothing because it thinks it is up while the slave is down, so no issues. But Node 2 thinks that master has gone down and so is the primary shard, so it will automatically elect itself as master and also promote the replica shard to a primary shard.
Now, the cluster gets into a confused zone and can result in an inconsistent state. Indexing requests that will hit Node 1 will index data in its copy of the primary shard, while the requests that go to Node 2 will fill the second copy of the shard. This can result in situations like when searching for data: depending on the node the search request hits, results will differ.
How to Avoid Elasticsearch Split Brain
As explained earlier, split brain problem can cause the two copies of the shard to be diverged and it may be impossible to realign them without a full reindexing.
elasticsearch.yml file has the solution to this problem as highlighted below:
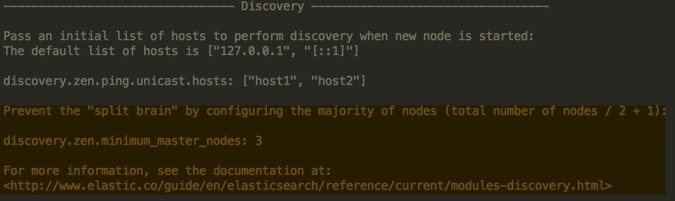
To avoid the split-brain situation, we make use of the discovery.zen.minimum_master_nodes parameter. This parameter determines how many nodes need to be in communication in order to elect a master. The elasticsearch.yml (which we download from Elastic.co and we don’t use it with PeopleSoft) does not specify and value for this parameter but the PeopleSoft Elasticsearch DPK specifies a value of 3 for this parameter. So, which is the correct value?
Elastic recommends that this should be set to N/2 + 1, where N is the number of nodes in the cluster. For example in the case of a 3 node cluster, discovery.zen.minimum_master_nodes should be set to 3/2 + 1 = 2 (rounding down to the nearest integer). Setting discovery.zen.minimum_master_nodes will avoid the split brain problem. It may seem like this setting tells Elasticsearch that it can have multiple master nodes but it actually tells Elasticsearch how many nodes in a cluster must be eligible to become a master before the cluster is in a healthy state.
For production environment, the recommendation is to plan for a 3 node cluster and set the discovery.zen.minimum_master_nodes to 2, limiting the chance of the split brain problem, but still keeping the high availability advantage. If a network failure causes one node to disappear from the other two nodes, the side with one node cannot see enough master-eligible nodes and will realize that it cannot elect itself as master. The side with two nodes will elect a new master and continue functioning correctly. As soon as the network issue is resolved, restarting the node will rejoin it to the cluster and start serving requests again.